publications
2025
-
 Closed-Loop Supervised Fine-Tuning of Tokenized Traffic ModelsZhejun Zhang, Peter Karkus, Maximilian Igl, Wenhao Ding, Yuxiao Chen, Boris Ivanovic, and Marco PavoneIn Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025
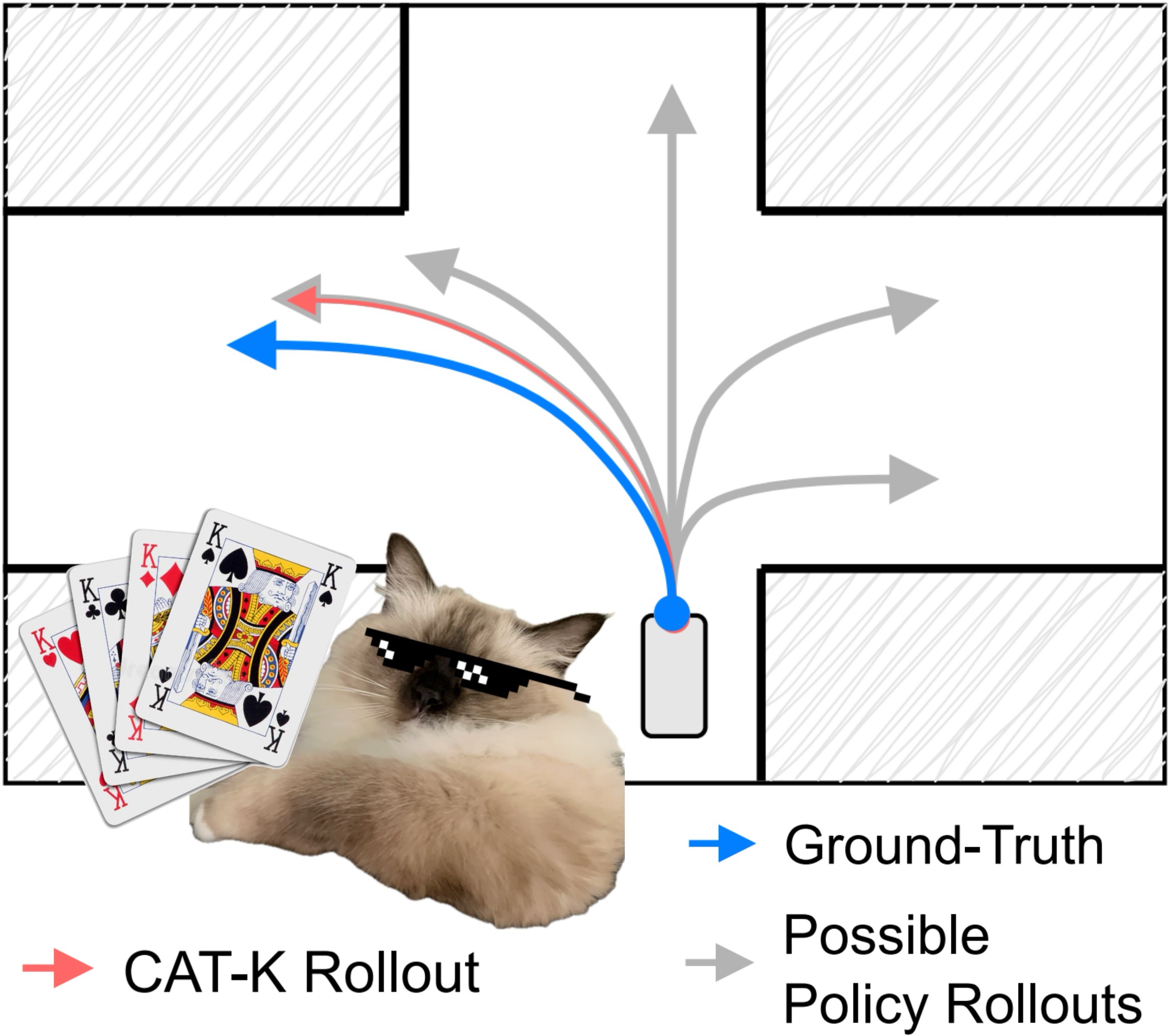
Closed-Loop Supervised Fine-Tuning of Tokenized Traffic ModelsZhejun Zhang, Peter Karkus, Maximilian Igl, Wenhao Ding, Yuxiao Chen, Boris Ivanovic, and Marco PavoneIn Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025Traffic simulation aims to learn a policy for traffic agents that, when unrolled in closed-loop, faithfully recovers the joint distribution of trajectories observed in the real world. Inspired by large language models, tokenized multi-agent policies have recently become the state-of-the-art in traffic simulation. However, they are typically trained through open-loop behavior cloning, and thus suffer from covariate shift when executed in closed-loop during simulation. In this work, we present Closest Among Top-K (CAT-K) rollouts, a simple yet effective closed-loop fine-tuning strategy to mitigate covariate shift. CAT-K fine-tuning only requires existing trajectory data, without reinforcement learning or generative adversarial imitation. Concretely, CAT-K fine-tuning enables a small 7M-parameter tokenized traffic simulation policy to outperform a 102M-parameter model from the same model family, achieving the top spot on the Waymo Sim Agent Challenge leaderboard at the time of submission.
@inproceedings{zhang2025closed, title = {Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models}, author = {Zhang, Zhejun and Karkus, Peter and Igl, Maximilian and Ding, Wenhao and Chen, Yuxiao and Ivanovic, Boris and Pavone, Marco}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, }
2024
-
 TrafficBots V1.5: Traffic Simulation via Conditional VAEs and Transformers with Relative Pose EncodingZhejun Zhang, Christos Sakaridis, and Luc Van GoolarXiv preprint arXiv:2406.10898 2024
TrafficBots V1.5: Traffic Simulation via Conditional VAEs and Transformers with Relative Pose EncodingZhejun Zhang, Christos Sakaridis, and Luc Van GoolarXiv preprint arXiv:2406.10898 2024In this technical report we present TrafficBots V1.5, a baseline method for the closed-loop simulation of traffic agents. TrafficBots V1.5 achieves baseline-level performance and a 3rd place ranking in the Waymo Open Sim Agents Challenge (WOSAC) 2024. It is a simple baseline that combines TrafficBots, a CVAE-based multi-agent policy conditioned on each agent’s individual destination and personality, and HPTR, the heterogeneous polyline transformer with relative pose encoding. To improve the performance on the WOSAC leaderboard, we apply scheduled teacher-forcing at the training time and we filter the sampled scenarios at the inference time.
@article{zhang2024trafficbots, title = {TrafficBots V1.5: Traffic Simulation via Conditional VAEs and Transformers with Relative Pose Encoding}, author = {Zhang, Zhejun and Sakaridis, Christos and Van Gool, Luc}, journal = {arXiv preprint arXiv:2406.10898}, year = {2024}, } -
 Real-Time Motion Prediction via Heterogeneous Polyline Transformer with Relative Pose EncodingAdvances in Neural Information Processing Systems (NeurIPS) 2024
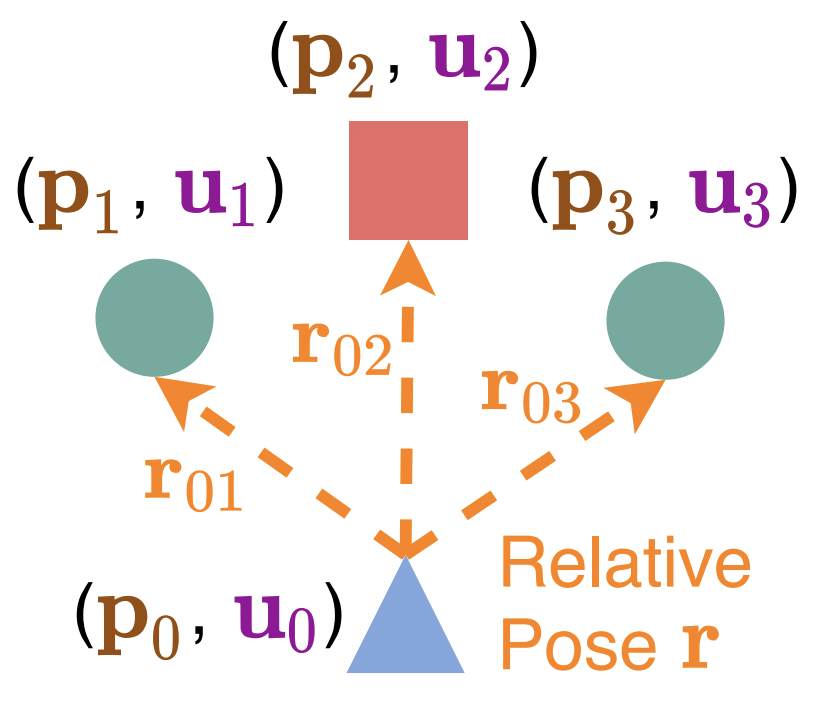
Real-Time Motion Prediction via Heterogeneous Polyline Transformer with Relative Pose EncodingAdvances in Neural Information Processing Systems (NeurIPS) 2024The real-world deployment of an autonomous driving system requires its components to run on-board and in real-time, including the motion prediction module that predicts the future trajectories of surrounding traffic participants. Existing agent-centric methods have demonstrated outstanding performance on public benchmarks. However, they suffer from high computational overhead and poor scalability as the number of agents to be predicted increases. To address this problem, we introduce the K-nearest neighbor attention with relative pose encoding (KNARPE), a novel attention mechanism allowing the pairwise-relative representation to be used by Transformers. Then, based on KNARPE we present the heterogeneous polyline Transformer with relative pose encoding (HPTR), a hierarchical framework enabling asynchronous token update during the online inference. By sharing contexts among agents and reusing the unchanged contexts, our approach is as efficient as scene-centric methods, while performing on par with state-of-the-art agent-centric methods. Experiments on Waymo and Argoverse-2 datasets show that HPTR achieves superior performance among end-to-end methods that do not apply expensive post-processing or ensembling.
@article{zhang2024hptr, title = {Real-Time Motion Prediction via Heterogeneous Polyline Transformer with Relative Pose Encoding}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, author = {Zhang, Zhejun and Liniger, Alexander and Sakaridis, Christos and Yu, Fisher and Van Gool, Luc}, year = {2024}, }

2023
-
 TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion PredictionIn International Conference on Robotics and Automation (ICRA) 2023
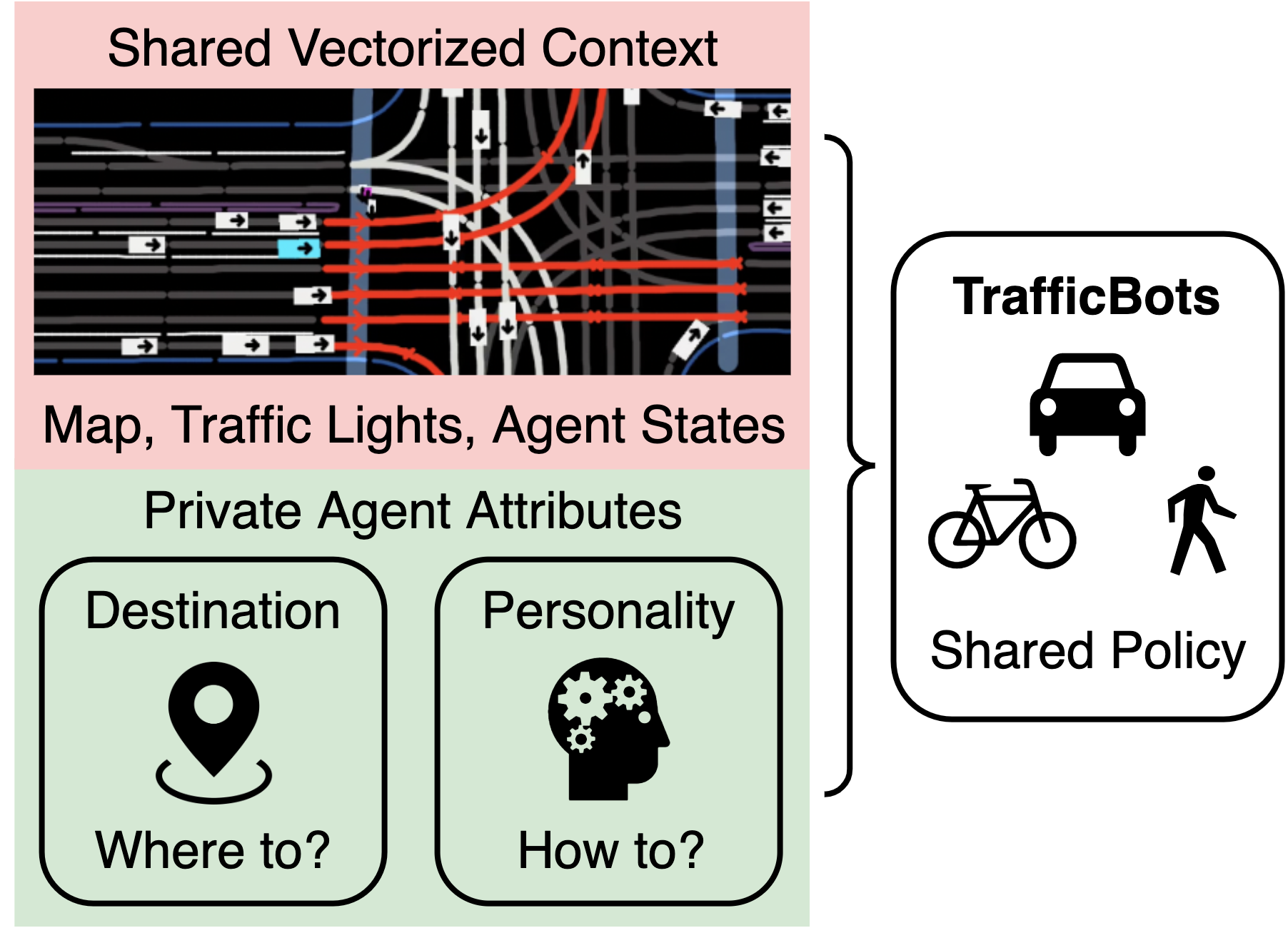
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion PredictionIn International Conference on Robotics and Automation (ICRA) 2023Data-driven simulation has become a favorable way to train and test autonomous driving algorithms. The idea of replacing the actual environment with a learned simulator has also been explored in model-based reinforcement learning in the context of world models. In this work, we show data-driven traffic simulation can be formulated as a world model. We present TrafficBots, a multi-agent policy built upon motion prediction and end-to-end driving, and based on TrafficBots we obtain a world model tailored for the planning module of autonomous vehicles. Existing data-driven traffic simulators are lacking configurability and scalability. To generate configurable behaviors, for each agent we introduce a destination as navigational information, and a time-invariant latent personality that specifies the behavioral style. To improve the scalability, we present a new scheme of positional encoding for angles, allowing all agents to share the same vectorized context and the use of an architecture based on dot-product attention. As a result, we can simulate all traffic participants seen in dense urban scenarios. Experiments on the Waymo open motion dataset show TrafficBots can simulate realistic multi-agent behaviors and achieve good performance on the motion prediction task.
@inproceedings{zhang2023trafficbots, title = {TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction}, booktitle = {International Conference on Robotics and Automation (ICRA)}, author = {Zhang, Zhejun and Liniger, Alexander and Dai, Dengxin and Yu, Fisher and Van Gool, Luc}, year = {2023}, patent = {https://data.epo.org/gpi/EP4296898A1}, } -
 A Multiplicative Value Function for Safe and Efficient Reinforcement LearningIn International Conference on Intelligent Robots and Systems (IROS) 2023
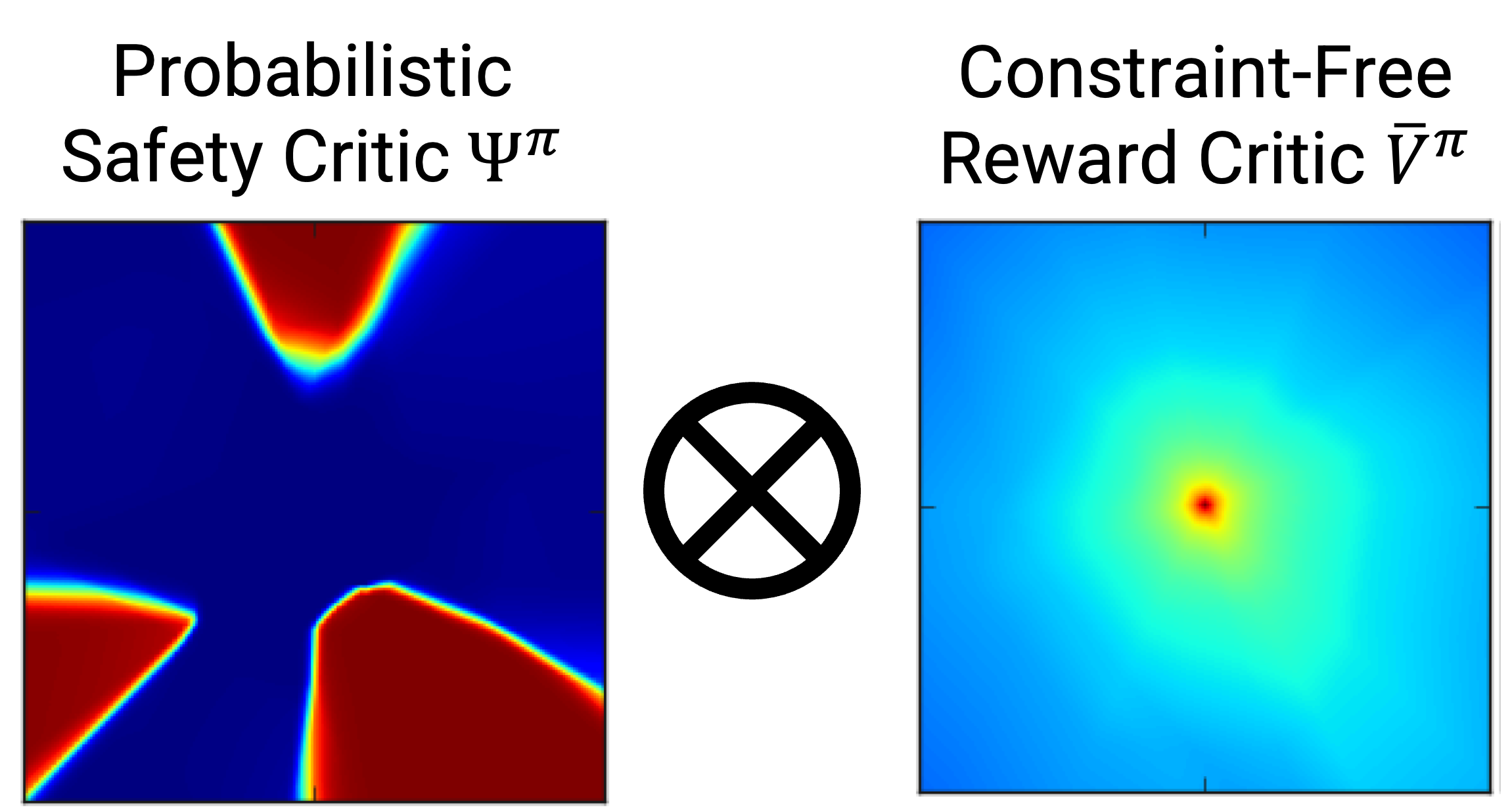
A Multiplicative Value Function for Safe and Efficient Reinforcement LearningIn International Conference on Intelligent Robots and Systems (IROS) 2023An emerging field of sequential decision problems is safe Reinforcement Learning (RL), where the objective is to maximize the reward while obeying safety constraints. Being able to handle constraints is essential for deploying RL agents in real-world environments, where constraint violations can harm the agent and the environment. To this end, we propose a safe model-free RL algorithm with a novel multiplicative value function consisting of a safety critic and a reward critic. The safety critic predicts the probability of constraint violation and discounts the reward critic that only estimates constraint-free returns. By splitting responsibilities, we facilitate the learning task leading to increased sample efficiency. We integrate our approach into two popular RL algorithms, Proximal Policy Optimization and Soft Actor-Critic, and evaluate our method in four safety-focused environments, including classical RL benchmarks augmented with safety constraints and robot navigation tasks with images and raw Lidar scans as observations. Finally, we make the zero-shot sim-to-real transfer where a differential drive robot has to navigate through a cluttered room.
@inproceedings{buehrer2023multiplicative, title = {A Multiplicative Value Function for Safe and Efficient Reinforcement Learning}, booktitle = {International Conference on Intelligent Robots and Systems (IROS)}, author = {B{\"u}hrer, Nick and Zhang, Zhejun and Liniger, Alexander and Yu, Fisher and Van Gool, Luc}, year = {2023}, }
2021
-
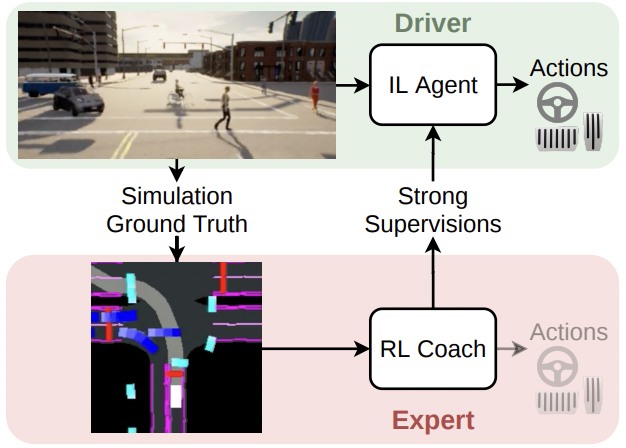 End-to-End Urban Driving by Imitating a Reinforcement Learning CoachIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2021
End-to-End Urban Driving by Imitating a Reinforcement Learning CoachIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2021End-to-end approaches to autonomous driving commonly rely on expert demonstrations. Although humans are good drivers, they are not good coaches for end-to-end algorithms that demand dense on-policy supervision. On the contrary, automated experts that leverage privileged information can efficiently generate large scale on-policy and off-policy demonstrations. However, existing automated experts for urban driving make heavy use of hand-crafted rules and perform suboptimally even on driving simulators, where ground-truth information is available. To address these issues, we train a reinforcement learning expert that maps bird’s-eye view images to continuous low-level actions. While setting a new performance upper-bound on CARLA, our expert is also a better coach that provides informative supervision signals for imitation learning agents to learn from. Supervised by our reinforcement learning coach, a baseline end-to-end agent with monocular camera-input achieves expert-level performance. Our end-to-end agent achieves a 78% success rate while generalizing to a new town and new weather on the NoCrash-dense benchmark and state-of-the-art performance on the challenging public routes of the CARLA LeaderBoard.
@inproceedings{zhang2021roach, title = {End-to-End Urban Driving by Imitating a Reinforcement Learning Coach}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, author = {Zhang, Zhejun and Liniger, Alexander and Dai, Dengxin and Yu, Fisher and Van Gool, Luc}, year = {2021}, patent = {https://data.epo.org/gpi/EP4124995A1}, }